Manual for Fluviz v2.0
This document describes the use and the possibilities of the data processor Fluviz.Fluviz is useful to generate, alter and analyse spatial data (e.g. digital elevation models, or land coverage information). It is mainly written as a compagnion to two-dimensional surface flow models. The main options are:
- File reads data from ASCII-files and exits the program.
- Edit for editing existing data sets.
- Map for surface interpolation (gridding) and mapping of nodes.
- Set displays and performs operations on structured data sets (grids).
- Export saves data sets in various file formats.
The plotting in Fluviz is performed by routines that are derived from the interactive grafic library GraficV3. These routines enable to plot lines, vectors, contours (mono and color) and animated plots. Drivers are available for X11 and Postscript. The Keep file option allows to overlay previously stored grafical data and bitmap data (pbm-format). Grafic features such as lines and filled polygons can be stored in Data Exchange Format (DXF).
File
 FILE reads ASCII-data from files. The data can be structured (grids)
or
unstructured (points and vertices).
FILE reads ASCII-data from files. The data can be structured (grids)
or
unstructured (points and vertices).
Usually the original data is unstructured, e.g. random distributed points and vertices. LOAD reads from a file and overwrites existing data. If the data are stored on different files, ADD reads from these files without removing the existing data.
The syntax of the ASCII-file is:
>>unstruct is used for unstructured data input.
xyz i1 i2 i3 is unstructured input given in x,y,z coordinates. The
r11 r12 r13 i1, i2 and i3 defines the number of the columns where
r21 r22 r23 the x, y and z values are stored, respectively.
. . . (Defaults: i1=1, i2=2, i3=3)
lines defines break lines given as polygons, where the x,y,z
r11 r12 r13 i1 values are stored in the first, second and third column.
r21 r22 r23 i2 A point that is a start point of the polygon is flagged
in the fourth column with an integer (e.g. i=1, else
i=0).
cs 'name' r1 r2
r11 r12 is a record for the cross-section definition.
r12 r22 The name of the cross-section (character*8) is ignored.
. . r1[km] is a distance along the river (ignored) and r2[m]
is the elevation of the bed level. The offset (i.e.
distance from the left border) is stored in the first
column and the bed level is stored in the 2nd column.
locate r1 r2 r3 is used to locate sections. r1[m],r2[m] are the x,y
coordinates of the origin of the section, and r3[degree]
is the angle of the section measured clock wise from the
y-axis.
item 'name' can be used to identify the following data record.
move r1 r2 translates nodes and lines to east (r1) and north (r2).
rotate r rotates the coordinate system in clock-wise direction
with the angle r [degree] with the origin as centre.
xclip r1 r2 range of clipping area in x-direction (values outside
are ignored).
yclip r1 r2 range of clipping area in y-direction (values outside
are ignored).
>>grid is used for structured input.
nx i is the number of grids in x-direction.
ny i is the number of grids in y-direction.
xllcorner r r[m] is the x-coord of the lower-left corner.
yllcorner r r[m] is the y-coord of the lower-left corner.
dx r r[m] is the distance between grid lines in
x-direction.
dy r same as for dx but in y-direction.
item 'name' is followed by a list of nx*ny values.
row1 ...
row2 ...
>> denotes the end of the input. Any further input is
ignored.
Edit
The EDIT option allows to process unstructured data sets. The main options are:
- Filter: buffering of points close to vertices; weeding of vertices (recursive Douglas-Peuker algorithm); cleaning of points with same co-ordinates; closing of polygons
- Alter: defining operations (+,-,*,/,<,>) that are applied to the all given nodes or nodes within a polygon defined by vertices. The READ option allows to read the operator and the polygon information from a file. The syntax for such a file is:
fill =1.0The keyword end is used to separate polygons on the same file.
x1 y1 fills the area of the polygon defined by the x/y co-ordinates
x2 y2 with the value 1.0.
. .
. .
fill +1.0
x1 y1 adds the value 1.0 to the area defined by the closed polygon.
x2 y2
. .
. .
Example I: Fill an area with the constant value of 0.04 (e.g. Manning value):
fill =0.04Example II: Add 10 meters to the nodes within the two polygons given below.
691550 272415
691717 272433
691864 272509
691873 272667
691857 272663
691830 272558
fill + 10.0
691393 272300
691423 272342
691455 272379
691503 272393
691551 272405
end
691550 272415
691717 272433
691864 272509
691873 272667
Map
 The Map option allows to transform data from unstructured into
structured
data format. After reading the unstructured data (using the FILE
commands) an interpolation algorithm is applied to create a
structured
rectangular grid. The interpolation is used as the points of the new
grid
do not coincide with the given data points.
The Map option allows to transform data from unstructured into
structured
data format. After reading the unstructured data (using the FILE
commands) an interpolation algorithm is applied to create a
structured
rectangular grid. The interpolation is used as the points of the new
grid
do not coincide with the given data points.
The following interpolation methods can be used:
- NEAREST looks for the nearest point in the neighbourhood and takes its value for the new point.
- INVERSE DISTANCE: The value of the grid point is estimated by the weighted average of the given points within a circle with a specified radius. The weight of each point is proportional to the inverse of the squared distance to the centre point of the circle (i.e. the grid point). If no point is found within the search radius the maximum value of all the given points is taken. Note that a large search radius gives smoother grids.
- TIN uses a triangulation method for gridding. The triangulation mesh is defined in an element file that has to be created by an appropriate tool (e.g. by the shareware program Triangle that does the Delaunay triangulation). The input files (i.e. the .node and .poly files) can be generated with the EXPORT options.
- Load terrain points and vertices in given format
- Edit values and define boundary points (if necessary)
- Export values in .node and .poly format (e.g. test.node, test.poly) and exit
- Run Triangle e.g. with:
- Load the newly created test.1.node file as a point file into Fluviz
- Choose the Map/Tin option and define the grid size etc. Input the name of the created element file (e.g. test.1.ele).
- After the triangulation a name for the data item must be defined (e.g. bedlevel)
- Store the result on an external file (otherwise it is lost when you exit).
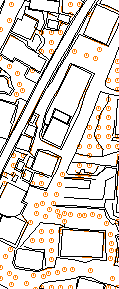
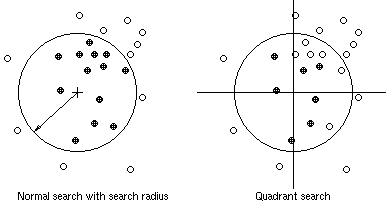
A special method of searching is quadrant search, where not more than two points are taken for interpolation in each quadrant (see Figure below). This search method is recommended in most cases as it balances the weighting from different directions.
These are the steps for a triangulation with Fluviz:
triangle -cp test(see the manual of Triangle for more details)
 The Map suboption allows to perform operations on a TIN surface.
The Map suboption allows to perform operations on a TIN surface.
- Alter: For operations on z-values of the TIN nodes ( see operations for unstructured data in the EDIT option).
- Map: Allows to map a .node file or unstructured data sets on a TIN.
- Inquire: To query z-values for given points and vertices. The input is either points and sections from the cursor or co-ordinates from a file (with x- and y-values in the 1st and 2nd row, respectively). The Channel option allows to query the geometry of cross-sections along a channel axis that is read from a file.
Set
SET enables to display GIS-like plots of grid data and to perform some basic operations and function to structured data sets.- MOVE for a shift of the x-y coordinates
- ABSOLUTE values of a set
- SLOPE and ASPECT operations for a terrain model
- MAXIMUM value of two sets
- MINIMUM value of two sets
- DIFFERENCE between two sets
Export
 The results from PRE can be exported in different file formats:
The results from PRE can be exported in different file formats:
- JUST stores results on a file that can be read by Hydro2de.
- XYZ stores results on file with the x- and y-coordinates in the 1st and 2nd column, and the parameter value in the 3rd column.
- GIS prints value to a file with the point number in the 1st column, the x- and y-coordinates in the 2nd and 3rd column, and the parameter value in the 4th column.
- ADASSPOINT stores point values of results in ADASS format.
- ADASSPOLY stores polygon values of grid cells in ADASS format.
- NODE/POLY is used to store unstructered data in .node and .poly format to be used in TRIANGLE.
- UNSTRUCTstores points and vertices for input into Fluviz..
- OMIT asks for a real number. Data points with smaller values are omitted when printed to the files specified above.
(c) 2021 fluvial.ch